ChatGPT, ou plus précisément le modèle qui se trouve derrière – soit GPT-3.5 ou GPT-4, selon la version utilisée – est une IA générative. Autrement dit, il s’agit d’un système qui génère du contenu à partir d’une entrée, communément appelée un « prompt ».


Le domaine des IA génératives connait depuis quelques années une véritable explosion, avec une croissance exponentielle du nombre de modèles et de leurs performances. Ces systèmes peuvent générer du texte, à l’image de GPT (on parle alors de « large language model », ou LLM), mais aussi des images, de la voix, de la musique, des vidéos, des modèles 3D, etc. Cette explosion a été permise par la combinaison de hardware puissant à des prix abordables (GPU dotés de milliers de cœurs et de dizaines de Go de mémoire RAM) et d’algorithmes de réseaux neuronaux hautement parallélisés, exploitant pleinement les capacités de ce matériel.
Un envol de perroquets stochastiques
La tâche basique d’un LLM peut se résumer simplement : étant donné un texte d’entrée, prédire une suite de mots qui a du sens pour compléter ce texte.
Cela peut amener à penser que ChatGPT ne comprends en fait pas ce qu’il écrit et qu’il se limite à de la prédiction statistique. C’est techniquement correct (ce qui a conduit certains détracteurs à qualifier les LLMs de « perroquets stochastiques »), mais cette vision est probablement incomplète pour au moins deux raisons : la représentation interne des mots utilisée par les LLMs cherche à capturer leur sens sémantique, et les capacités requises pour écrire un texte par prédiction amènent ces modèles à exhiber des comportements émergents.
Les embeddings : une manière de capturer le sens des mots
Les LLMs utilisent une représentation interne des mots et des phrases, appelée « embedding », qui essaie de capturer leur sens sémantique. Chaque texte est découpé en mots ou fragments de mots (tokens), et à chacun de ces tokens est associé un vecteur, l’embedding.
Ci-contre un exemple simplifié d’embedding.
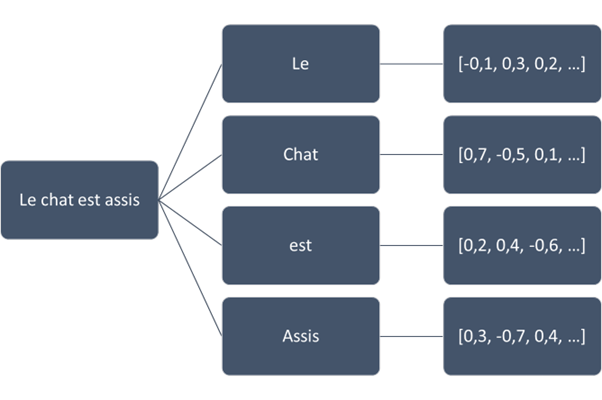
Un embedding est un vecteur de n dimensions (GPT en utilise 1536). Chacune de ces dimensions n’a pas de signification particulière en soi, mais l’ensemble constitue une sorte de signature pour le mot ou le fragment de mot qu’il représente. La distance vectorielle entre deux embeddings est alors indicative de la similarité sémantique entre les mots correspondants. Par exemple, les mots « raquette » et « tennis » vont probablement avoir des embeddings rapprochés, tout comme les mots « raquette » et « neige », tandis que la distance entre « tennis » et « neige » sera plus importante.
Mais comment sont calculés ces embeddings ? Ils sont le fruit de l’entraînement d’un réseau neuronal sur des volumes colossaux de textes divers (livres, pages wikipedia, réseaux sociaux, etc.), de l’ordre de 1000 milliards de mots. Au fil de cet entrainement, le réseau neuronal apprend à capturer le sens sémantique des mots dans des embeddings.
Les LLMs ont donc bien une forme de compréhension des mots qu’ils manipulent, bien que limitée à leur sens sémantique, c’est-à-dire tel qu’il est représenté par le langage. La compréhension humaine est plus large et s’enrichit largement de notre expérience du monde réel. Par exemple, une personne s’attend naturellement à ce qu’une pomme tombe d’un arbre vers le sol plutôt que vers le ciel, grâce à notre expérience physique de la gravité. Le réseau neuronal d’un LLM peut acquérir une forme de compréhension de la gravité, mais uniquement s’il est entrainé avec suffisamment de texte en décrivant ses effets.
Réseaux neuronaux et comportements émergents
Écrire un texte mot-à-mot en se basant sur une prédiction statistique est un défi majeur ! Les mots d’un texte entretiennent des relations multiples et complexes, qui peuvent s’étendre d’un bout à l’autre d’une phrase, voire à travers un texte entier. Essayez par exemple d’écrire un texte en utilisant uniquement les mots proposés par la frappe prédictive de votre téléphone.

L’algorithme derrière cette frappe prédictive est incapable d’écrire de manière cohérente. Pour cela, des capacités bien plus sophistiquées, comme celles d’un réseau neuronal doté de milliards de paramètres, sont nécessaires.
Or lorsque le réseau neuronal d’un LLM devient suffisamment grand, il peut commencer à exhiber des comportements émergents, c’est-à-dire des comportements pour lesquels il n’a pas été explicitement entraîné.
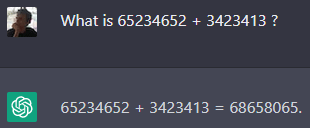
Prenons un exemple simple avec GPT-3.5. Si vous lui demandez « Que fait 2+2 ? », il vous répondra 4, ce qui peut s’expliquer par le fait qu’il a « vu » l’équation 2+2=4 de nombreuses fois dans ses données d’entraînement. Mais si vous lui demandez de résoudre une addition de deux grands nombres aléatoires, il vous donnera le plus souvent une réponse exacte. Pourtant, cette addition exacte n’existe très probablement pas dans ses données d’entraînement, et l’algorithme de l’addition n’a pas été explicitement programmé dans ChatGPT. Cela signifie qu’à force de rencontrer des additions dans ses données d’entraînement, le réseau neuronal de GPT a fini par « comprendre » et reproduire les règles de cette opération
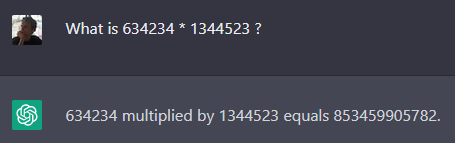
En revanche, avec une multiplication de deux grands nombres arbitraires, GPT-3.5 ne donne généralement pas la réponse exacte, bien qu’il s’en approche. Dans l’exemple ci-dessous, le résultat correct est 852 742 200 382 (alors que GPT donne 853 459 905 782). Le réseau neuronal de GPT a appris à estimer le résultat d’une multiplication, mais pas à le calculer exactement.
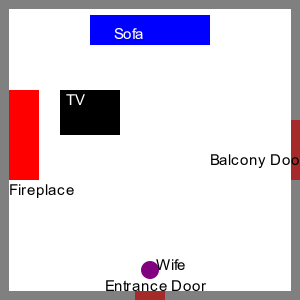
GPT-4, doté d’un réseau neuronal beaucoup plus grand que celui de GPT-3.5 (bien que la taille précise ne soit pas connue, OpenAI ne communiquant pas cette information), a des capacités de raisonnement émergentes encore plus importantes. Il est par exemple capable de « comprendre » la description d’un agencement d’objets dans l’espace, de répondre à des questions sur cet agencement depuis des points de vue différents, et même d’en fournir une représentation graphique simplifiée (en passant par un format d’image à représentation textuelle, tel que le SVG).
Conclusion : avancées et limites des LLMs
En conclusion, les capacités des LLMs récents, tels que GPT-3.5 et GPT-4, constituent une avancée majeure dans le domaine de l’intelligence artificielle générative. Malgré le fait qu’ils opèrent sur la base de prédictions statistiques de séquences de mots, leur compréhension sémantique des mots et leurs capacités émergentes de raisonnement démontrent une forme de compréhension du langage qui va au-delà de la simple répétition des textes sur lesquels ils ont été entrainés. Il convient de garder à l’esprit que ces systèmes, aussi sophistiqués soient-ils, restent limités à une compréhension du langage dérivée des textes sur lesquels ils ont été entraînés, et ne possèdent pas une expérience du monde réel comme un être humain.
Malgré ces limites, ces systèmes d’IA ouvrent la voie à des applications sans précédent, en permettant à des utilisateurs d’interagir avec des systèmes informatiques par langage naturel. Dans le prochain article de cette série, nous nous intéresserons au prompt engineering, domaine cherchant à tirer le maximum des capacités des IA génératives.

Yann Fontana
Architecte data
Partager sur :

