Le domaine du prompt engineering (ou ingénierie des prompts) a vu le jour avec le développement des IA génératives. Ces IA produisent la plupart du temps du contenu à partir d’une entrée initiale, le prompt. Pour un LLM, ce prompt est généralement au format textuel, bien que certains modèles puissent accepter des médias tels que des images ou des sons, voire une combinaison de ces différents formats (on parle alors de modèle multimodal).


Le domaine des IA génératives connait depuis quelques années une véritable explosion, avec une croissance exponentielle du nombre de modèles et de leurs performances. Ces systèmes peuvent générer du texte, à l’image de GPT (on parle alors de « large language model », ou LLM), mais aussi des images, de la voix, de la musique, des vidéos, des modèles 3D, etc. Cette explosion a été permise par la combinaison de hardware puissant à des prix abordables (GPU dotés de milliers de cœurs et de dizaines de Go de mémoire RAM) et d’algorithmes de réseaux neuronaux hautement parallélisés, exploitant pleinement les capacités de ce matériel.
Cet article se divise en deux parties : la première présente des techniques de base de prompt engineering, la deuxième décrit des manières de combiner ces techniques pour esquisser de vraies applications augmentées par LLM.
Pourquoi est-ce utile ?
Le prompt a un impact significatif sur le rendu du modèle utilisé. À travers ce prompt, le modèle doit comprendre les intentions de l’utilisateur afin de produire un résultat qui correspond au mieux à ce qu’il cherche à obtenir : c’est ce que l’on appelle l’alignement du modèle. Les modèles tels que ChatGPT ont été entraînés pour s’aligner au mieux (grâce à des techniques décrites dans le dernier article de cette série), mais leur capacité à le faire, et donc à produire des résultats pertinents, dépend fortement des informations contenues dans le prompt.
Le prompt engineering permet donc de maximiser la qualité et l’utilité des résultats obtenus par les modèles d’IA générative. Les modèles les plus performants possèdent des capacités de génération très poussées, mais encore faut-il savoir les exploiter.
Quelques techniques de base
Les quelques techniques décrites ici sont applicables à des LLM entrainés pour suivre les instructions d’un utilisateur, tels que GPT-3.5 et GPT-4. Lors de cet entrainement, de nombreux exemples d’instructions et de réponses associées ont été soumises au modèle.
Par exemple :
- Prompt : « Write a short story in third person narration about a protagonist who has to make an important career decision. »
- Réponse : « John was at a crossroads in his life. He had just graduated college and was now facing the big decision of what career to pursue. After much deliberation […] »
Pour obtenir les meilleures réponses, il est conseillé de formuler ses prompts de manière similaire aux données d’entrainement.
- Donner des instructions claires et précises au modèle. Dans l’exemple ci-dessous, l’utilisateur demande à GPT-4 de respecter un format très précis dans ses réponses, afin de générer du code DOT pour GraphViz (une manière de représenter un diagramme sous forme textuelle). Une fois le format décrit, il demande à GPT-4 de donner le code d’un diagramme avec 8 entités représentant le cycle de l’eau.
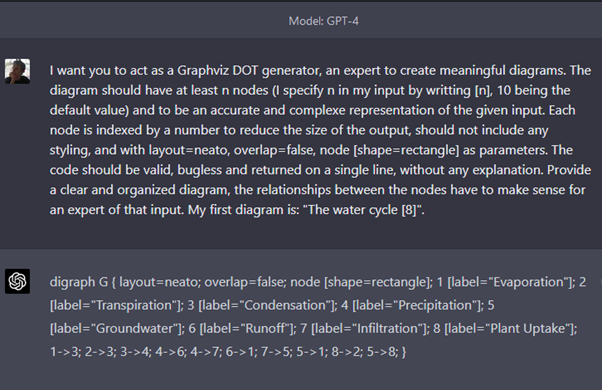
Le code DOT donné en réponse par GPT-4 a la représentation graphique suivante :

Demander au modèle d’ajuster sa réponse : un LLM comme GPT-4 permet d’interagir pour ajuster des résultats, explorer des alternatives, affiner certains aspects… Par exemple ci-dessous, l’utilisateur demande à GPT-4 de réécrire le diagramme précédent en “Mermaid”, un autre langage de représentation de diagramme, en ajoutant des emojis d’illustration.
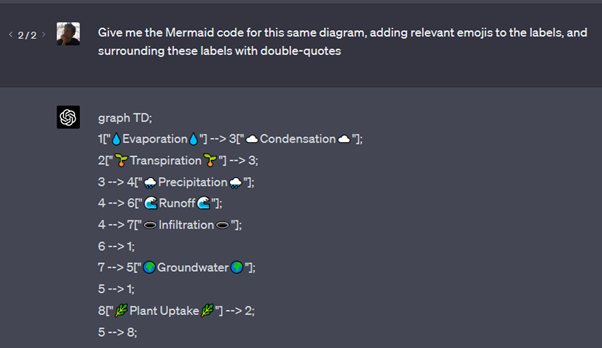
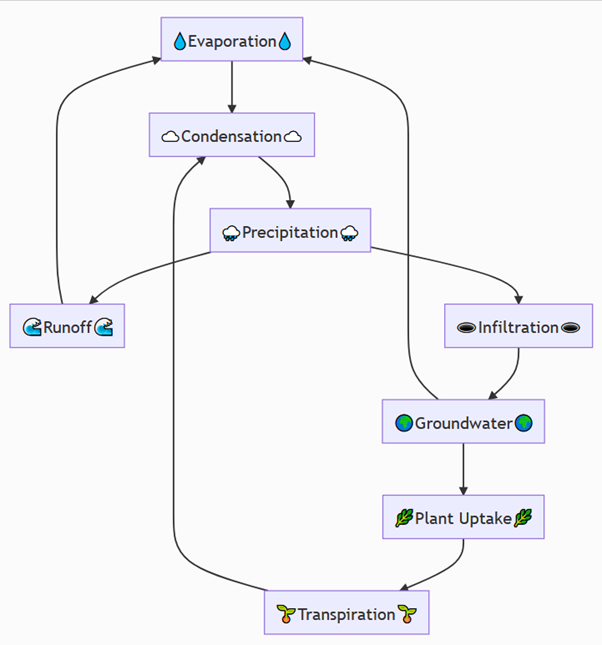
Ce code “Mermaid” a la représentation graphique suivante :
Donner une identité au modèle peut fortement affecter le format et le contenu des réponses. Comparez ainsi les réponses à la même question, lorsque l’utilisateur donne trois identités différentes au modèle.
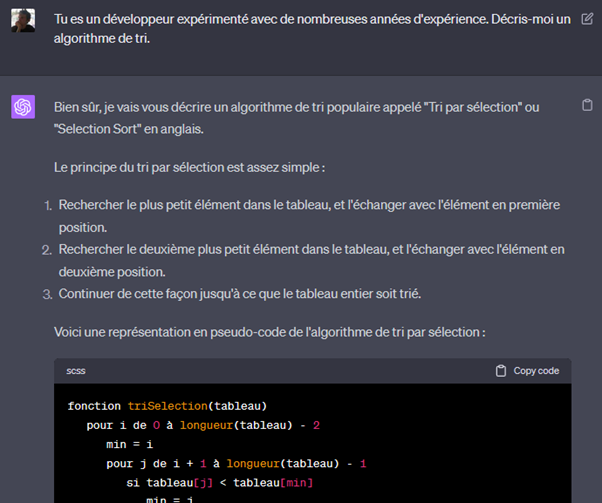


Le « programmeur » répond avec des phrases courtes et précises, explique l’algorithme avec du pseudo-code, et donne même des indications sur la complexité algorithmique (non montré par la capture d’écran). Le « lycéen » tutoie l’utilisateur, utilise un vocabulaire plus informel et un peu moins précis et décrit l’algorithme par des phrases. L’IA « grincheuse » répond bien à la question, mais questionne nos choix dans la vie…
De manière générale, il est conseillé d’attribuer au modèle une identité d’expert dans le domaine de la question posée.
- Demander au modèle de vérifier ses propres résultats. Les réponses d’un LLM peuvent parfois souffrir de mésalignement (la réponse n’est pas alignée avec ce qu’attendait l’utilisateur) et d’hallucinations (le modèle invente des faits). La nature même des LLMs ne permet pas d’éviter de manière certaine et définitive ces comportements, de la même manière qu’une personne peut parfois répondre à une question de manière erronée. Demander au modèle de réaliser une étape de réflexion, lors de laquelle il porte un regard critique sur sa propre réponse, permet néanmoins de réduire ces comportements. Là encore, il y a des similarités avec une personne humaine, qui peut, par exemple, repérer ses propres erreurs en se relisant.
Après avoir vu l’ensemble de ces techniques, nous pouvons nous demander comment développer des applications augmentées par LLM ? C’est ce que nous verrons dans la deuxième partie de l’article, publiée prochainement.

Yann Fontana
Architecte data
Partager sur :

