Seconde partie de notre article sur le prompt engineering. Après avoir présenté les techniques de base dans la première partie, nous décrivons ici comment combiner ces techniques pour esquisser des applications augmentées par LLM.

Dépasser les limites des LLMs grâce au prompt engineering
Les techniques présentées dans la première partie de cet article sont principalement applicables aux interactions directes entre un utilisateur et un LLM. Cependant, elles ouvrent également la possibilité de créer des chaînes d’interactions plus complexes, donnant naissance à de véritables applications « LLM-powered ».
Si vous avez passé un peu de temps à utiliser ChatGPT, vous avez probablement pris conscience des limitations suivantes :
- ChatGPT n’est pas « connecté » à Internet, il ne connait pas d’informations postérieures à la fin de ses données d’entrainement (qui s’arrêtent actuellement en septembre 2021)
- Il ne connait que des informations publiques, il ne peut donc pas être utilisé pour poser des questions sur les données internes d’une entreprise
- La taille de son prompt est limitée. Il n’est par exemple pas possible de lui copier / coller un texte de 50 pages et de lui demander de le résumer.
Ces limites peuvent être contournées ou minimisées, lorsque les bonnes techniques de prompt engineering sont mises en œuvre.
Apprendre l’usage d’outils à un LLM
Comme montré dans la première partie de cet article, un LLM suffisamment puissant est capable de respecter des formats spécifiques pour écrire ses réponses. Ces formats peuvent être, par exemple, une requête SQL, ou bien une requête à un webservice REST.
L’exemple ci-dessous montre qu’avec un prompt approprié, GPT-3.5 est capable de « comprendre » la documentation d’un webservice (ici un service de météo) et d’écrire des appels conformes à cette documentation.
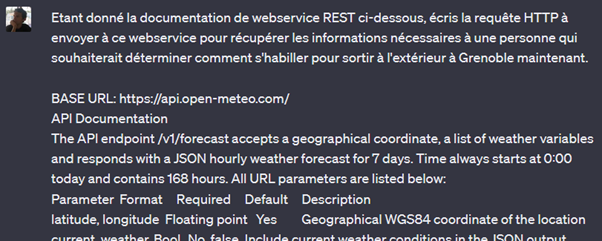
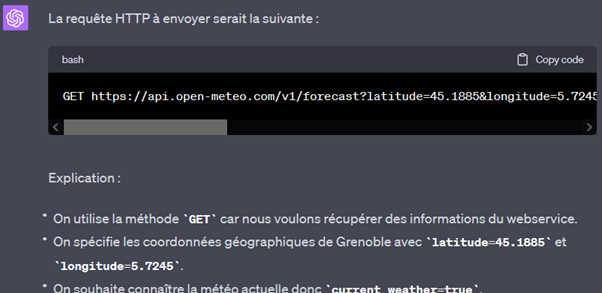
Avec un prompt demandant à GPT de retourner uniquement la requête HTTP, puis un peu de code pour envoyer cette requête automatiquement au webservice et permettre à GPT de récupérer les résultats pour les interpréter, les deux sont interfacés : GPT dispose alors d’un outil qu’il peut utiliser pour répondre à une requête d’un utilisateur.
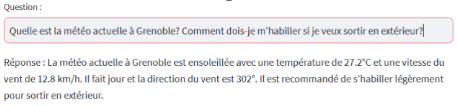
Cela rend possible la mise à disposition d’outils pour un LLM. Dans ce contexte, un outil est un système avec lequel le LLM peut interagir grâce à un prompt approprié, et qui répond aux requêtes formulées par le LLM. Voici quelques exemples d’outils et d’applications potentielles :
- Un outil d’interrogation de pages web, permettant à un LLM d’interroger un moteur de recherche et d’en exploiter les résultats.
- Un outil d’interrogation de BDD, qui permet à un utilisateur de formuler des requêtes en langage naturel à cette BDD (le LLM se chargeant de la traduction en SQL).
- Un outil d’environnement d’exécution Python, qui permet à un LLM d’écrire et d’exécuter du code sans intervention humaine.
Les applications potentielles sont vastes. Le prochain article de cette série explorera l’une d’entre elles plus en détail.
La puissance du contexte
Nous avons jusqu’ici parlé de prompt pour désigner les requêtes envoyées à un LLM. Pour être plus précis, un prompt peut comprendre des instructions sur ce que le LLM doit générer, mais aussi des informations complémentaires de contexte, pour permettre d’améliorer la qualité de la réponse : c’est ainsi le cas dans l’exemple de la section précédente, lorsque la documentation de l’API météo est fournie au LLM. Ces informations complémentaires forment le contexte d’une requête au LLM.
Ce contexte permet de communiquer tout type d’information que le modèle ne possède pas dans ses données d’entrainement, ou même des informations qu’il possède déjà mais que l’on veut renforcer.
Quelques exemples d’utilisation du contexte :
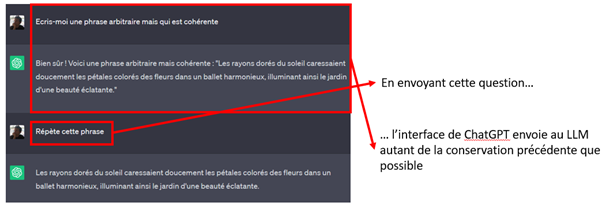
- Un LLM est stateless, c’est-à-dire qu’il ne retient pas d’informations d’une requête à l’autre. Pour pouvoir « dialoguer » avec un LLM, il faut avec chaque nouveau message lui envoyer les messages précédents en contexte, afin qu’il puisse écrire une réponse cohérente avec le fil de la conversation. Lorsqu’on utilise ChatGPT, l’interface fait cela de manière transparente.
- Fournir au LLM des informations qu’il ne peut pas connaitre car trop récentes. Par exemple, demander à ChatGPT les raisons de la hausse de l’inflation en 2022 ne produit pas de réponses très pertinentes, étant donné que ses données d’entrainement s’arrêtent en septembre 2021. En revanche, lui poser la même question en lui copie-collant la page Wikipedia « Inflation en 2021-2023 » lui permet de formuler une réponse à partir des informations contenues dans cette page (avec la limite que la qualité de la réponse dépendra fortement de celle de la page Wikipedia).
- Fournir au LLM des informations qu’il ne peut pas connaitre car elles ne sont pas publiques. Par exemple, pour utiliser ChatGPT pour poser des questions sur un document privé d’entreprise, il serait possible d’en copier-coller le contenu en contexte des questions (en mettant pour l’instant de côté les questions de confidentialité de l’information, qui seront couvertes dans le dernier article de cette série).
Cette manière d’utiliser le contexte est parfois appelée « context stuffing » (remplissage de contexte). Il s’agit d’une alternative au fine-tuning de modèle, c’est-à-dire à l’entrainement de modèles génériques sur des données particulières. Là où le fine-tuning demande l’intervention de data scientists et l’utilisation de ressources de calcul, le context stuffing demande seulement de manipuler le contexte.
Le context stuffing se heurte cependant vite à une limite : la taille du contexte des modèles est limitée, et pour ceux facturés par requête, cette facturation est proportionnelle au nombre de mots du contexte.
| Modèle | Taille maximum du contexte | Facturation de l’entrée |
| GPT-3.5 16K | ~ 12 000 mots | 0.001 $ / 750 mots |
| GPT-4 Turbo | ~ 96 000 mots | 0.01 $ / 750 mots |
Taille maximum du contexte et facturation de l’entrée des modèles GPT actuels
De plus, les LLM ne disposent pas d’une attention illimitée : si une grande quantité d’informations est passée en contexte mais que seulement quelques phrases sont pertinentes pour répondre à l’utilisateur, il n’est pas certain que le LLM soit capable d’extraire et exploiter ces quelques informations pertinentes.
L’article suivant de cette série décrit comment il est possible de composer avec cette limite, permettant l’utilisation de GPT pour interroger des données privées de grand volume.
Conclusion : Transformer les interactions Homme-Machine grâce au prompt engineering
Le prompt engineering joue un rôle crucial pour exploiter le potentiel complet des IA génératives. Il permet d’améliorer l’alignement et la qualité des résultats générés. Les techniques de base de prompt engineering constituent un point de départ essentiel pour l’exploitation efficace des capacités des LLM.
En outre, le prompt engineering ouvre des horizons passionnants pour la création d’applications « LLM-powered ». L’interfaçage avec des outils et l’utilisation optimisée du contexte ouvre la voie à des applications avec lesquelles un utilisateur interagit par langage naturel, plutôt qu’avec des interfaces ou des langages spécialisés. L’utilisateur pourra alors réellement « dialoguer » pour interroger une base de données, analyser un document, recherche de l’information dans une base de connaissance, etc.
Dans le prochain article de cette série, nous explorerons plus en détails un de ces cas d’usage, en esquissant l’architecture d’un système d’interrogation de données d’entreprise.

Yann Fontana
Architecte data
Partager sur :

