L’article précédent de cette série présentait des techniques de prompt engineering, permettant d’améliorer les résultats obtenus des IA génératives et de créer des applications augmentées par LLM. Cet article décrit un exemple de mise en œuvre de ces techniques, dans une application d’exploitation d’une base de connaissance d’entreprise.

L’application : interroger une base de connaissance
Nous souhaitons pouvoir interroger l’ensemble des articles du blog Hardis. Nous ne voulons pas juste un moteur de recherche, mais pouvoir vraiment poser des questions en langage naturel sur les sujets traités dans ces articles, et obtenir des réponses à partir de ceux-ci. Nous souhaitons également que les réponses soient sourcées, afin de pouvoir les vérifier.
Nous ne pouvons pas poser ces questions à ChatGPT, pour les raisons suivantes :
- Certains articles du blog sont postérieurs à la date limite des données d’entrainement de ChatGPT.
- Il est impossible de savoir si les articles antérieurs à cette date limite font partie des données d’entrainement de GPT. Même si c’est le cas, ils sont « diluées » dans la masse énorme de ces données, et il serait difficile de faire en sorte que GPT donne une réponse spécifiquement à partir de ces articles.
- ChatGPT n’est pas très performant pour sourcer ses réponses.
Nous ne pouvons pas non plus copier-coller la totalité des articles en contexte des questions. Le blog Hardis contient plus de 230 articles, le total dépasserait largement la taille maximum du contexte.
Une possibilité alternative consiste à mettre en œuvre ce qui est aujourd’hui couramment appelé de la génération augmentée de récupération (en anglais retrieval augmented generation, ou RAG). Le principe général est le suivant : lorsqu’un utilisateur soumet une question, le système trouve les articles ou fragments d’articles dont le thème est le plus similaire à cette question, et inclut ces données dans le contexte de la requête au LLM. L’utilisation du contexte du LLM est ainsi optimisée, en n’y incluant que des données avec une haute probabilité de pertinence pour répondre à la requête de l’utilisateur.
Comment réaliser les calculs de similarité nécessaires à cette technique ? Plusieurs méthodes existent, mais l’une des plus efficaces consiste à utiliser les embeddings. Comme expliqué dans le premier article de cette série, des sections de texte avec un contenu sémantique similaire ont des embeddings relativement proches.
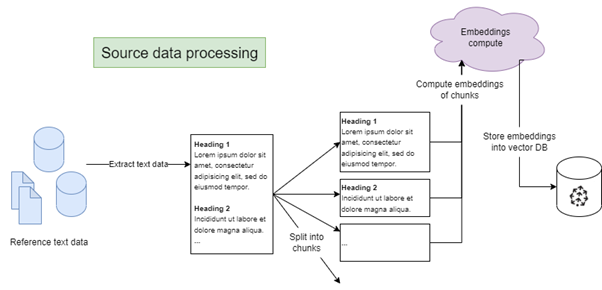
Ingestion et préparation des données
Pour pouvoir réaliser ces calculs de similarité, une étape initiale d’ingestion et de préparation des données sources est nécessaire :
- Récupération des données: dans notre exemple, une librairie de scraping (par exemple BeautifulSoup) peut récupérer le texte des articles de blog.
- Découpage: selon la taille de contexte disponible et la longueur des articles, il peut être utile de les découper en fragments, afin de ne donner que les sections les plus pertinentes au LLM. Plusieurs stratégies de découpage peuvent être appliquées (tous les N mots, après chaque titre d’un certain niveau, avec ou sans recouvrement entre les fragments, etc.). Là encore, des librairies permettent de réaliser facilement ce découpage (par exemple LangChain).
- Calcul d’embedding : l’embedding de chaque fragment est calculé, par exemple par appel de l’API OpenAI Ada v2. Pour chaque fragment de texte soumis, l’API renvoie un vecteur à 1536 dimensions.
- Stockage des embeddings : chaque embedding est stocké dans une base de données, avec le fragment d’article associé. Pour faciliter les opérations sur les embeddings, une base de données vectorielles est préférée (telle que Pinecone ou PostgreSQL avec le plugin pg-vector).
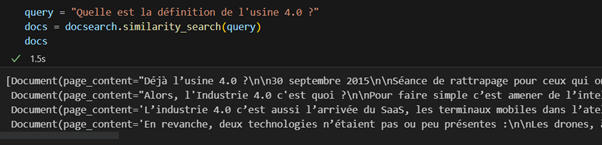
Une fois alimentée, la BDD vectorielle est capable de répondre à une requête de similarité.
Par exemple, pour la question « Quelle est la définition de l’usine 4.0 ? », l’embedding de cette question peut être calculé, puis une requête peut être exécutée sur la BDD pour récupérer les fragments dont les embeddings ont les distances vectorielles les plus faibles avec cette question.
Interrogation des données
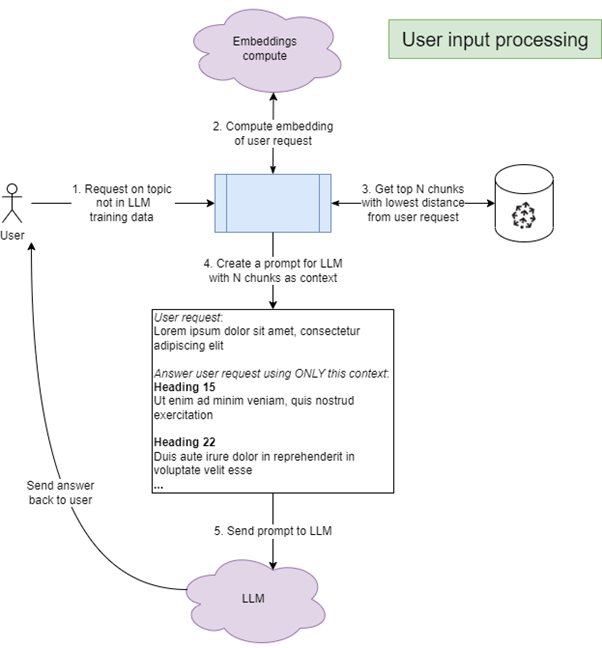
Une fois les données ingérées et préparées dans la base vectorielle, les requêtes d’utilisateurs peuvent être traitées. Pour chaque requête :
- Calcul d’embedding de la requête
- Récupération dans la base vectorielle des fragments avec la distance la plus faible à la requête
- Construction d’un prompt pour le LLM, avec un format du type suivant :
« Réponds à la question ci-dessous en utilisant uniquement les informations données en contexte. Donne les sources de ta réponse au format SOURCES : source1 source2.
***Question : <question>
***Informations de contexte :
*Source 1 : <titre article>
*Contenu : <texte article>
*Source 2 : <titre article>
[…] »
En action :

Conclusion : des limites mais un potentiel important
Cet article montre comment il est possible d’utiliser dès aujourd’hui ChatGPT pour interroger des données spécifiques, qui ne se trouvent pas nécessairement dans ses données d’entrainement, avec des réponses sourcées.
Ce type de système peut dès aujourd’hui répondre à de vrais cas d’usage d’entreprise. Un cas d’usage en pleine expansion est ainsi la création de chatbots permettant d’interroger une documentation technique.
Tel que présenté ci-dessus, des limites existent cependant :
- Le système fait confiance à l’utilisateur pour poser des questions pertinentes par rapport aux données sources. Des questions sur des sujets complètement différents peuvent donner des réponses moins prévisibles, dépendant de l’interprétation du LLM.
- L’étape de recherche par similarité fonctionne au mieux pour des questions sur des sujets précis, pour lesquels une réponse peut être apportée à partir de sections spécifiques des données sources. Pour des questions plus globales, ou portant sur des métadonnées (par exemple : « Quels sont les thèmes les plus couramment traités par le blog Hardis ? », « Quel est l’article le plus long du blog ? »), d’autres types de systèmes doivent être mis en place.
- Selon le type de requêtes auxquelles le modèle devra répondre et selon le type des données sources, un fine-tuning de modèle (c’est-à-dire le réentrainement d’un modèle générique pour un cas d’usage particulier) pourra donner de meilleurs résultats. Mais le fine-tuning de modèles demande d’investir dans des compétences et des ressources de calcul spécialisées.
Les possibilités sont nombreuses et les gains de productivité potentiels élevés, mais le domaine reste très novateur et le besoin d’expertise pour mettre en place des systèmes réellement utiles pour leurs utilisateurs reste important.

Yann Fontana
Architecte data
Partager sur :
